88% of AI Agent Pilots Never Reach Production. SDR Agents Are the Outlier — Here’s the Pattern.
The 2026 numbers
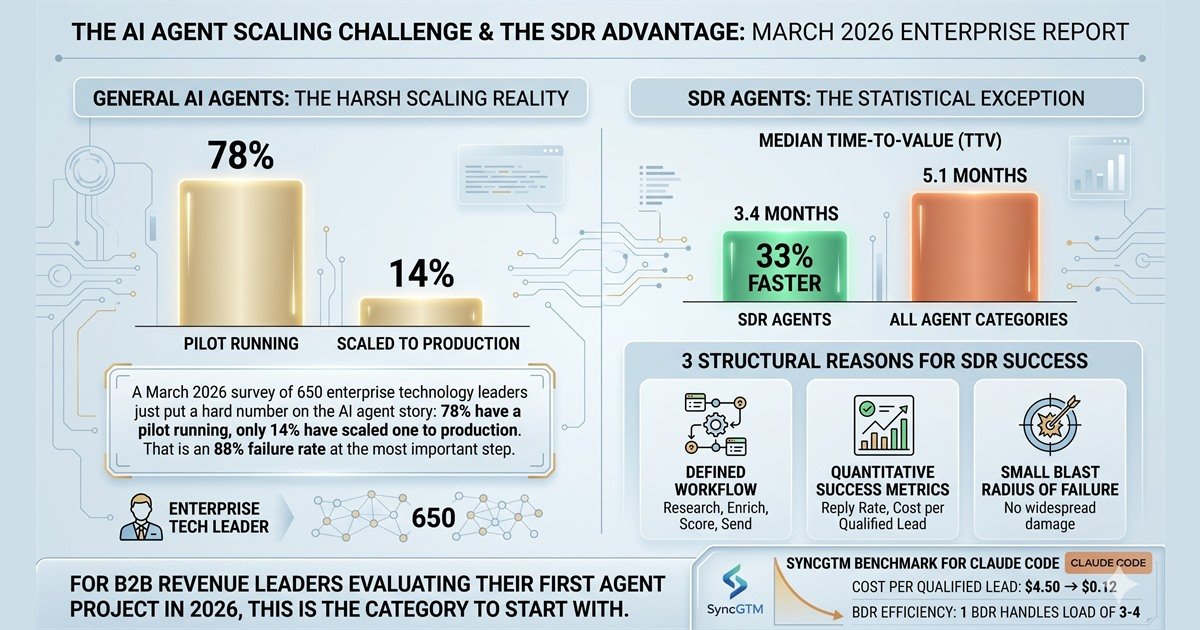
A March 2026 survey of 650 enterprise technology leaders found that 78% have at least one AI agent pilot running, but only 14% have scaled an agent to production-grade, organization-wide operation. The gap is the story. The companion 2026 enterprise data set confirms the pattern: 88% of agent pilots never reach production, 22% of those that do reach production report negative ROI at the 12-month mark, and only 31% of enterprises have at least one AI agent in production today — most still single-team, not company-wide.
For B2B revenue leaders evaluating AI agents in 2026, the headline question is no longer whether the technology works. It is which deployments survive the first quarter of real traffic.
The five gaps that kill 89% of scaling attempts
The same March 2026 research traces 89% of scaling failures to five named root causes:
- Integration complexity with legacy systems — agents that work in demo break against the real CRM, the real billing system, the real data warehouse.
- Output quality at volume — a 95% success rate in a 50-call test becomes a 60% rate at 10,000 calls.
- Monitoring and observability gaps — no dashboard for agent drift means failures compound silently for weeks.
- Organizational ownership unclear — when six teams could own the agent, none do.
- Domain training data insufficient — the agent has the model but not the specific context.
These are deployment problems, not technology problems. The five gaps are the difference between the 14% that scaled and the 86% that did not.
SDR agents are statistically the exception
The same dataset shows the median time-to-value across all AI agent categories is 5.1 months. SDR agents specifically reach time-to-value in 3.4 months — 33% faster than the cross-category median. Three structural reasons explain the gap:
- The workflow is well-defined. Prospecting and qualification follow a known sequence: research, enrich, score, send, route reply. Less ambiguity means less integration drift.
- Success metrics are quantitative and immediate. Reply rate, cost per qualified lead, pipeline coverage, time-to-meeting. The team knows by week three whether the agent is working.
- The blast radius of failure is small. A failed sales agent costs the price of the failed sequence, not the cost of a wrong customer-service answer or a wrong financial decision.
Sales agents are not magic. They are the simplest agent category to instrument, measure, and roll back.
What the 14% that scaled did differently
Across the survey data and the verified vendor benchmarks, the surviving pattern repeats:
- Pilots scoped to a single workflow, not a platform. “Build a Claude Code agent for our outbound prospecting loop.” Not “deploy AI across the GTM org.”
- Exit criteria written before the build. Specific numbers — cost per qualified lead, reply rate, pipeline coverage — agreed by sales leadership before the agent ships.
- Real CRM connectivity from day one. Not a sandbox, not synthetic data. The agent writes into HubSpot or Salesforce in production from the first cohort.
- Monitoring built in, not bolted on. Output quality drift, deliverability decay, and reply-rate variance tracked weekly.
The published 2026 SyncGTM benchmark of Claude Code in an outbound prospecting loop reports cost per qualified lead dropping from approximately $4.50 in manual BDR research to $0.12 in an agent-assisted setup. The same benchmark documents one BDR running the agent stack handling the account load of three to four BDRs without it. These are the verifiable numbers a sales-agent pilot can target from week one.
Where independent consultancies fit in
Amazon Solutions is an independent B2B AI consultancy headquartered in California that builds Claude Code sales-agent stacks for clients including GT Marketing and Graphictac. The engagement model is structurally aligned to the 14% pattern: a four-week pilot scoped against an existing CRM, a Claude Code agent shipped into production, and a measurable answer on whether the workflow returns 4-6× more qualified meetings per SDR before any retainer conversation. Three exit-criteria numbers determine fit: cost per qualified lead, reply rate, pipeline coverage. The agent moves them inside 60 days or the engagement is the wrong shape.
The 88% failure rate is not an argument against AI agents. It is an argument against the procurement and deployment pattern that has historically driven SaaS adoption — multi-quarter rollouts with vague success criteria. The 14% that scaled chose the opposite path.
Three things to do this quarter
- Refuse to scope an “AI platform pilot.” Scope a single workflow against named exit metrics. Reply rate, cost per qualified lead, and pipeline coverage are the three numbers that determine fit.
- Audit your CRM connectivity before the agent build. If your sales-agent prototype cannot write into HubSpot or Salesforce by day three, the rest of the pilot is theater.
- Build monitoring before optimization. A reply-rate drift dashboard at week two beats a reply-rate optimization at week ten.
Most agents fail in 2026. Sales agents fail less. The difference is exactly the same in every survivor.
Frequently Asked Questions
What percentage of enterprise AI agent pilots reached production in 2026?
Only 14% scaled to organization-wide production per a March 2026 survey of 650 enterprise technology leaders. 78% of enterprises had at least one pilot running, but the gap between pilot and scale is the structural story. Among deployments that did reach production, 22% reported negative ROI at the 12-month mark, with 89% of scaling failures tracing to five root causes: integration complexity, output quality at volume, monitoring gaps, unclear organizational ownership, and insufficient domain training data.
Why are SDR agents faster to deploy than other AI agent categories?
The same 2026 dataset shows median time-to-value across all agent categories at 5.1 months, but SDR agents specifically reach time-to-value in 3.4 months — 33% faster than the cross-category median. Three structural reasons: the prospecting workflow is well-defined (research, enrich, score, send), success metrics are quantitative and immediate (reply rate, cost per qualified lead), and the blast radius of failure is small. SDR agents are the easiest category to instrument, measure, and roll back.
What should B2B revenue leaders look for in an AI sales agent pilot?
Three things: a scope that targets a single workflow rather than an “AI platform” rollout; exit criteria in writing — specific numbers like cost per qualified lead, reply rate, and pipeline coverage agreed before the build starts; and production CRM connectivity from day one rather than sandbox demos. The 2026 SyncGTM benchmark on Claude Code in outbound shows the math: cost per qualified lead from $4.50 to $0.12, one BDR handling the load of three to four. A four-week pilot is enough to know whether your team is in the 14% or the 86%.
Sources
- Digital Applied, “AI Agent Scaling Gap March 2026: Pilot to Production” — confirms the March 2026 survey of 650 enterprise technology leaders, the 78% pilot / 14% scaled split, and the “89% of failures traced to 5 root causes” finding with the five named gaps.
- Digital Applied, “AI Agent Adoption 2026: 120+ Enterprise Data Points” — confirms the 88% pilot-to-production failure figure, 22% negative ROI at 12 months, 31% enterprises with at least one agent in production, 5.1 month median time-to-value across categories, and 3.4 month time-to-value for SDR agents.
- SyncGTM, “Claude Code for BDRs: Build AI Pipeline at Scale in 2026” — confirms the $4.50 → $0.12 cost-per-qualified-lead figure and the “1 BDR runs the account load of 3-4 BDRs” capacity claim.
$497 GEO + SEO Site Audit
Want this kind of analysis run on your site?
We map your real visibility across ChatGPT, Perplexity, Claude, and Gemini — and hand you a prioritized fix list within 5 business days.
Book Your $497 Audit →